Adding a new Logging Source
Adding a new logging source is simple if the ELK stack is alreary installed. Follow the following steps:
Note
Even though this guide uses Filebeat as log collector, the principles should be the same for others as well.
1. Logging Source
Identify the logging source. For example, it required to track the users that log in to an SSH server. Identify where the service writes its logs. In this case
/var/log/secure.Knowing where to take the logs from, identify the messages that are useful. For example:
1Jun 25 15:30:02 elk sshd[5086]: pam_unix(sshd:session): session closed for user vagrant
2Jun 25 17:08:11 elk sshd[5185]: Accepted publickey for vagrant from 10.0.2.2 port 54128 ssh2: RSA SHA256:64u6q4IdjxSFhVGdqwJa60y/nMx7oZWb0dAsNqMIMvE
3Jun 25 17:08:11 elk sshd[5185]: pam_unix(sshd:session): session opened for user vagrant by (uid=0)
The first and third logs might not be useful in this case, but the second log is the one that helps.
2. Filtering
Now it’s time to parse and filter the important information. It can be accomplished using Logstash and the Kibana’s Grok debugging tool. Grok is a Logstash filtering plugin used to match patterns and extract useful information from the logs. For more information about Grok read the documentation. Follow these steps:
Open Kibana. Go to Dev Tools -> Grok Debugger. Here can be found three main text boxes:
The first one is where to put the log that will be filtered.
The second one is where a regular expression is written. This regular expression tells Grok how to filter the log.
The third one is where Grok shows its results in JSON format, which is the format used by Elasticsearch to inxed everything.
2. But, how to filter an arbitrary log?. Grok uses a regular expression library called Oniguruma.
This library has a way match patterns in the log. These patterns can be tagged with a name. That name is important because that is how the information will be found in Elasticsearch.
Here is the regular expression that matches the timestamp, the event state (if the user could or couldn’t log in), the user that tried to log in,
the ip address that is trying to log in, the port number and the user signature.
Check out the following regular expression:
%{SYSLOGTIMESTAMP:log_timestamp} %{SYSLOGHOST:system_hostname} sshd(.*)?: (?<sshd_event>[a-zA-Z]+) %{DATA:sshd_method} for (invalid user )?%{DATA:sshd_user} from %{IPORHOST:sshd_guest_ip} port %{NUMBER:sshd_guest_port} ssh2(: %{GREEDYDATA:sshd_guest_signature})?With the log in the first text box and the regular expression in the second text box, press Simulate. Up to this point the Kibana’s Grok debugger should look like this:
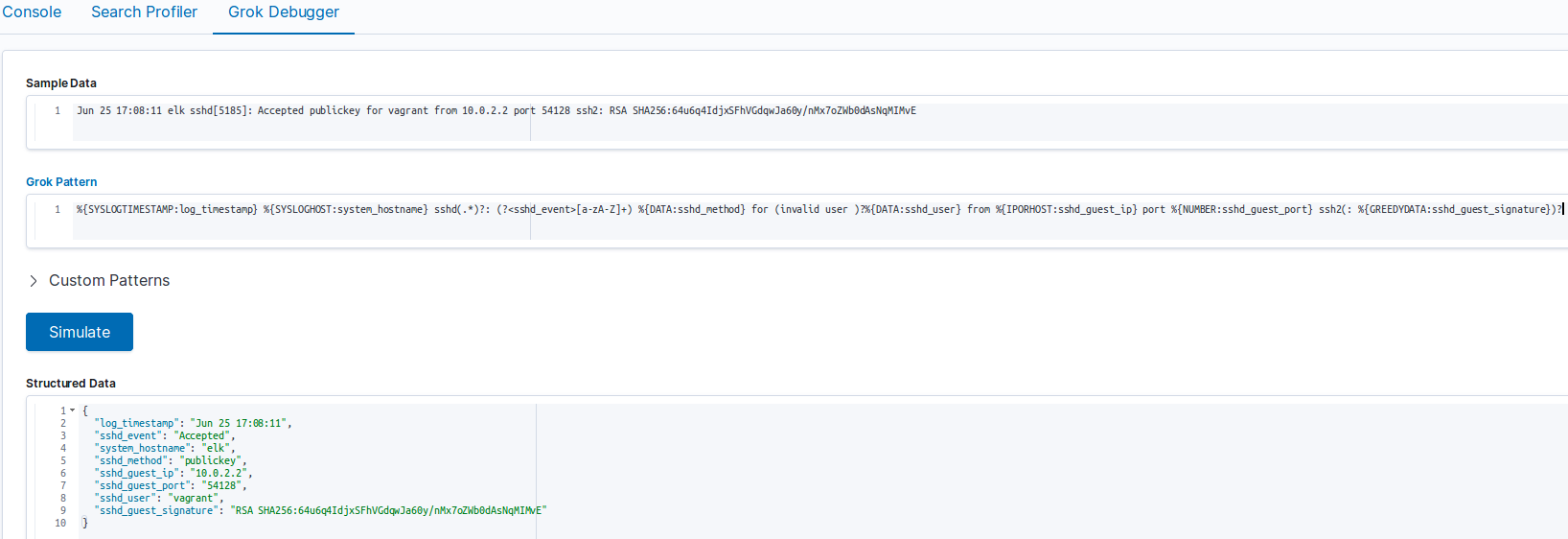
Let’s break down the regular expression into chunks:
%{SYSLOGTIMESTAMP:log_timestamp}: SYSLOGTIMESTAMP is a Grok built-in regular expression. These and many more built-in regular expressions can be found in this repository. log_timestamp is how was decided to tag the matched string. Therefore, this expression will match from Jun … to … 17:08:11.
%{SYSLOGHOST:system_hostname}: SYSLOGHOST matches the log hostname and identifies it as system_hostname. Note that this is the sshd server’s hostname, not the user’s hostname.
sshd(.*)?: This expression matches the literal string ‘sshd’, followed by anything except new lines (the dot) ‘.’. The parentheses are grouping operators, therefore, they group the expression ‘.*’, and this whole expression is optional, ‘?’, which means it might or might not appear in the log. In other words, there might not be something after the word ‘sshd’, if so, then it won’t match anything. Note that this expression doesn’t have any identifier, that’s because what’s matched here is not important.
(?<sshd_event>[a-zA-Z]+): This is an important expression. The expression ‘(?<xxx>…)’ can be used when there isn’t a default Grok pattern for what is needed. Instead of ‘xxx’, type the name/tag that will be given to the matched string. Instead of ‘…’ put the regular expression that matches the needed string. In this case, the event is composed only by letters, so ‘[a-zA-Z]’ means any lowercase or uppercase letter, the ‘+’ means one or more times. This expression can be replaced by the Grok default pattern %{DATA:sshd_event}, but for the purpose of this guide, ‘(?<xxx>…)’ was used so that it can be used whenever needed.
%{DATA:sshd_method}: DATA matches anything (but new lines). The key is that this anything may or may not appear, in other words, it’s optional. But sshd_method is always needed, why to let it as optional?. Well, it’s just for simplicity, instead of creating a new regular expression it’s simpler to just use the built-in %{DATA:…}.
(invalid user )?: If the event is ‘Invalid’ instead of ‘Accepted’ or ‘Failed’ this string appears, so that’s why it is optional.
%{DATA:sshd_user}: DATA matches anything (but new lines), but that anything may or may not appear.
%{IPORHOST:sshd_guest_ip}: IPORHOST matches IP addresses, including IPv6. That IP address is given the identifier sshd_guest_ip.
%{NUMBER:sshd_guest_port}: NUMBER matches numbers, in this case, the client’s port number.
(: %{GREEDYDATA:sshd_guest_signature})?: GREEDYDATA matches anything (but new lines). In this case, it matches the guest signature, but sometimes it might not appear, so that’s why it is enclosed in an optional construct ‘(…)?’.
The other expressions, ‘sshd’, ‘for’, ‘from’, ‘port’, and ‘ssh2’ are literal strings, so Grok has to find them in the string that is being parsed, otherwise the whole string is rejected.
Already having a way to parse the new log, it’s time to change the Logstash pipeline configuration. Before proceeding, it’s recommended to read this short guide about how a pipeline configuration file looks. Also, it would be very useful to read about what is the purpose of Logstash. Go to the end of the filter section and add the following:
if [fromsecure] { }If this this logging source,
/var/log/secure, was added before, don’t add thatifsentence, surely it is somewhere else in the filter section. But, why[fromsecure]?, what does that mean?. It checks if the JSON received has a field calledfromsecure. The existence of that field will be explained later in 4. Adding the log path to Filebeat.
Under the
ifsentence add agrokblock. This is the way of asking to Logstash to use a filter plugin, in this case Grok. So, add the following:
grok { match => { "message" => [] } add_field => {} }The
matchandadd_fieldsub-blocks ask Grok to use those options. Thematchoption is used to parse fields, what was explained two subsections before. Those fields are passed to thefiltersection by theinputsection, which in turn receives messages from a Filebeat service, or a Dead letter queue. Theadd_fieldadds fields to the JSON message in case that the match option successfully matched a string. This is useful in theoutputsection of the pipeline. This is useful to send to Elasticsearch only what was successfully parsed, and not everything that arrives at theinputsection.
Under the match sub-block and the brackets, and between double quotes, add the regular expression built with the Kibana’s Grok debugger. Under the
add_fieldsub-block add the following too:
grok { match => { "message" => [ "%{SYSLOGTIMESTAMP:log_timestamp} %{SYSLOGHOST:system_hostname} sshd(.*)?: (?<sshd_event>[a-zA-Z]+) %{DATA:sshd_method} for (invalid user )?%{DATA:sshd_user} from %{IPORHOST:sshd_guest_ip} port %{NUMBER:sshd_guest_port} ssh2(: %{GREEDYDATA:sshd_guest_signature})?" ] } add_field => { "type" => "secure_sshd_login_attempt" "secure_correctly_filtered" => "true" } }The
typefield serves to differentiate logs in the same index in Elasticsearch. For example,/var/log/securealso stores logs about the system security (e.g who executes sudo commands), not only logs about ssh. Thesecure_correctly_filteredis used in theoutputsection to send only the information that was correctly filtered.
7. The following filter plugin is extremely important to correctly visualize the information. Kibana uses a metafield, called @timestamp, to organize and show the information based on dates.
Logstash adds that field by default when a log is received in the input section. The problem is that the log_timestamp field that we added before has a different date, it has the timestamp that corresponds to the log creation.
The time when the log arrives to Logstash is likely to be very different from the time that the log was generated by the service (in this case sshd). There might be a difference of months, even years, because the log that is being indexed might be from the last month/year.
To solve this problem Logstash has a plugin called date. This plugin can be used to replace the information in the metafield @timestamp with any other field that has a timestamp, in this case log_timestamp.
It has more options than the two presented here. The basic usage is the following:
date { match => [ "log_timestamp", "MMM dd yyyy HH:mm:ss", "MMM d yyyy HH:mm:ss", "MMM dd HH:mm:ss", "MMM d HH:mm:ss" ] timezone => "America/Bogota" }The
matchoption tells the plugin to parse the field in the first string given in the array,log_timestamp. The following strings are the format in which the field to parse might be built. For example, “MMM dd yyyy HH:mm:ss”, means that thelog_timestampfield might be in the format: Three letter month, MMM. A two digit day, dd. A four digit year, yyyy. A two digit hour, HH. A two digit minutes, mm. And a two digit seconds, ss. The rest of the options tells to the plugin that thelog_timestampfield might have those variants.The
timezoneoption tells the plugin to update the timezone in the@timestampfield to the given timezone. Elasticsearch uses UTC as timezone. It cannot be changed, that is, Elasticsearch uses it to work properly. Even though we cannot change it, we can update the@timestampfield with our real timezone because Kibana converts it underneath to the browser’s timezone. Therefore, it is important to have the same timezone in the browser and in the logs.Note
This plugin is used by Grok only in case of successful parse of the log.
The following filter plugin is used to remove unnecessary fields from the JSON that will be sent to Elasticsearch. This is how to use it:
mutate { remove_field => ["fromsecure", "log_timestamp"] }The
remove_fieldoption is given a list of fields that will be removed.
The
fromsecurefield is used in theifsentence above, so it’s not needed anymore. The procedence of this field is explaned later in 4. Adding the log path to Filebeat.The
log_timestampis not needed anymore because we already have a field that contains the a timestamp,@timestamp.
Up to this point there is no need for more Logstash filters. Putting everything together should look like this:
1# /etc/logstash/conf.d/main_pipeline.conf 2 3input { 4 beats { 5 port => "5044" 6 } 7 8 # Events go to the dead_letter_queue when Elasticsearch response has 400/402 code 9 dead_letter_queue { 10 path => "/var/log/logstash/dead_letter_queue" 11 tags => ["recovered_from_dead_letter_queue"] 12 } 13} 14 15filter { 16 if [fromsecure] { 17 18 grok { 19 match => { 20 "message" => [ 21 # Login attemps 22 "%{SYSLOGTIMESTAMP:log_timestamp} %{SYSLOGHOST:system_hostname} sshd(.*)?: %{DATA:sshd_event} %{DATA:sshd_method} for (invalid user )?%{DATA:sshd_user} from %{IPORHOST:sshd_guest_ip} port %{NUMBER:sshd_guest_port} ssh2(: %{GREEDYDATA:sshd_guest_signature})?" 23 ] 24 } 25 add_field => { "type" => "secure_sshd_login_attempt" 26 "secure_correctly_filtered" => "true" } 27 } 28 29 # In case of successful parsing, the @timestamp field is updated with the parsed info 30 date { 31 match => [ "log_timestamp", "MMM dd yyyy HH:mm:ss", "MMM d yyyy HH:mm:ss", "MMM dd HH:mm:ss", "MMM d HH:mm:ss" ] 32 timezone => "America/Bogota" 33 } 34 35 mutate { 36 remove_field => ["fromsecure", "log_timestamp"] 37 } 38 } 39} 40 41output { 42 if [secure_correctly_filtered] { 43 elasticsearch { # Dead Letter Queue is only supported for elasticsearch output 44 index => "secure" 45 hosts => ["elk:9200"] 46 } 47 } 48}In summary:
The first section,
input, indicates to Logstash where it will receive logs from. In this case Filebeat, on port 5044, and something called the Dead Letter Queue. This is where logs that couldn’t be indexed go. For example, Logstash received a log, but Elasticsearch crashed, so the log couldn’t be indexed, then the log is written to the Dead Letter Queue allowing it to be reindexed later.The last block,
output, indicates to Logstash where it will send logs to. In this case Elasticsearch, which is in the hostelkon port9200, to the indexsecure. Elasticsearch indexes will be explained in 3. Creating Indexes and Mappings, think about them as tables where the logs will be registered.Note the
ifsentence in line 42. Recall theadd_fieldoption explained in the Grok filter, well it is used here to send logs to the proper index if and only if, they were correctly filtered by Grok.
10. Restart the Logstash service and hopefully, everything will work perfectly. Sometimes, the service seems to start correctly but it failed reading the pipeline configuration file (what was just written).
To check that everything is perfect check out the log when Logstash is starting, commonly /usr/share/logstash/logs/logstash-plain.log. Logs similar to these are a good signal:
[2019-07-03T10:04:46,238][INFO ][logstash.agent ] Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]} [2019-07-03T10:04:46,705][INFO ][org.logstash.beats.Server] Starting server on port: 5044 [2019-07-03T10:04:50,337][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
3. Creating Indexes and Mappings
Indexes are used by Elasticsearch to store the information sent by Logstash. Mappings are a way to structure that data using a JSON format. Let’s see an example to structue the log parsed above, for more information about mappings read here:
PUT /secure { "mappings":{ "properties":{ "type": { "type" : "keyword" }, "system_hostname":{ "type": "keyword" }, "sshd_guest_ip":{ "type": "ip" }, "sshd_guest_port":{ "type": "integer" }, "sshd_guest_signature":{ "type": "text" }, "sshd_event":{ "type": "keyword" }, "sshd_method":{ "type": "keyword" }, "sshd_user":{ "type": "keyword" } } } }Elasticsearch offers a REST API to manage the data. So, PUT inserts new information into Elasticsearch. Therefore, if there exists an index with the name secure, Elasticsearch will throw an error. In that case use POST, which is used to update the existing information. So, what does all that stuff mean?:
"mappings"refers to the property that describes the structure of the index.
"properties"as its name says, is used to describe the properties of the mappings.The rest of the items are the fields and its types. These fields describe the types of the information parsed in Logstash. For example:
"sshd_guest_ip"is the field that represents the ip address parsed from the logs. Its type is"ip". Elasticsearch has a built-in type called"ip"which eases the indexation and visualization of ip addresses.The
"type"field is useful to differentiate the logs sent from a single source, in this case/var/log/secure. Recall theadd_fieldoption under the Grok plugin in 2. Filtering, it was added the field: “type” => “sshd_login_attempt”. Therefore, in case of indexing the sudo commands logs, change this field to something like: “type” => “secure_sudo_command”. This is how to differentiate them easily.
4. Adding the log path to Filebeat
Now that the data is filtered and properly structured, it’s time to start sending it to Logstash. Go to the machine that has the Filebeat service, edit the file /etc/filebeat/filebeat.yml.
Under the section filebeat.inputs: add:
1- type: log 2 paths: 3 - /var/log/secure* 4 fields: 5 fromsecure: true 6 fields_under_root: trueWhat does it mean?:
The first line indicates the type of information that will be collected.
The second line indicates the paths where the new logging source is located, in this case
/var/log/, andsecure*matches all the logs that start with the name secure. This wildcard is used becase some logs have a date at the end of its name, so it will be painful to add over and over again a path when a log appears in/var/log/.The fourth line,
fields, indicates to Filebeat to add a new field in to the JSON sent to Logstash. Recall the firstifsentence in the 2. Filtering section. Well, this field is added so that all the different logging sources can be differentiated in Logstash.The last option,
fields_under_root, is used to add the fields under the root of the JSON, and not nested into a field calledbeat, which is the default behavior.Restart the Filebeat service and hopefully everything will work perfectly. Otherwise, recall to check the logs usually under
/usr/share/<service>/logsor under/var/log/<service>.
5. Create Index Patterns
With some data indexed in Elasticsearch, create Index Patterns. These are used by Kibana to match (using regular expressions) indexes and take the data that will be plotted from those indexes matched by some pattern.
Go to Management -> Index Pattern -> Create index pattern. Select its name/pattern, and as time filter field select "@timestamp".
6 . Plot the data
One of the easiest plots that can be created is a frequency histogram. Nevertheless, there are lots of more features that Kibana offers.
In Kibana go to Visualize, press the + button, select the type of visualization, in this case, Vertical Bar. Afther this, select the index pattern that corresponds to the secure logs. Then, to create a frequency historgram of the users that failed logging in follow these steps:
In the left hand side of the Kibana web page, there is a subsection called Buckets. Click on X-Axis.
As aggregation select Terms. For more information about Term aggregation.
As field select sshd_user.
As custom label write: User name.
Now instead of X-Axis select Add sub-buckes. Then select Split Series.
Here as aggregation select Terms again.
As field select sshd_event.
Now type the following in the bar that is in the upper part of the Kibana’s GUI, the Filters bar:
sshd_event : "Failed". This is called Kibana Query Language, it can be used to filter the data and plot only what is be useful. More information on this query language here, Kibana Query Language.Click on the play button in the left hand side of the Kibana’s GUI.
Save the visualization with a descriptive name, something like: [sshd] Failed attempts to log in.
In case of not having a Dashboard, create a new one, then add the visualization. Up to this point it should look something like:
